Full details @ Benchmarking for Public Health Surveillance tasks on Social Media with a Domain-Specific Pretrained Language Model (Naseem et al., 2022).
I collected and pre-processed 25 datasets from different social media platforms (e.g. Twitter, Reddit) that were related to public health surveillance tasks. Examples of these tasks include binary and/or multi-class classification of vaccine sentiment, depression, stress, etc.
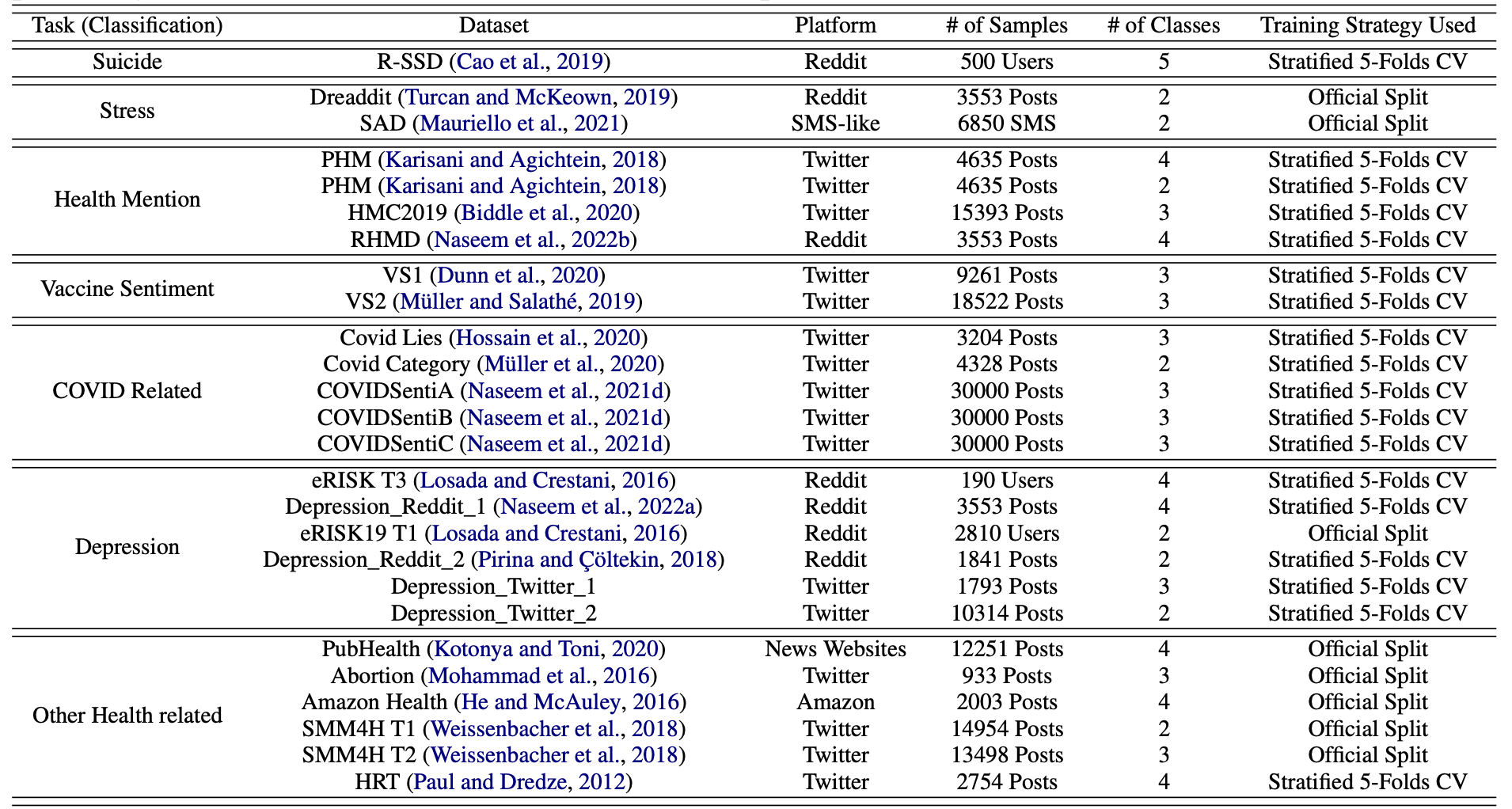
I then fine-tuned a pre-trained language model (PHS-BERT) on these tasks using ktrain (Tensorflow Keras library) and benchmarked the performance with other SOTA models (BERT, ALBERT, DistilBERT, BioBERT, CT-BERT, BERTweet, MentalBERT). All models were trained using the Adam optimiser and a one cycle policy at a maximum learning rate of 2e-05 with momentum cycle between 0.85 and 0.95. I used the Stratified 5-Folds cross-validation (CV) strategy for train/test split if the original datasets did not have an official train/test split.
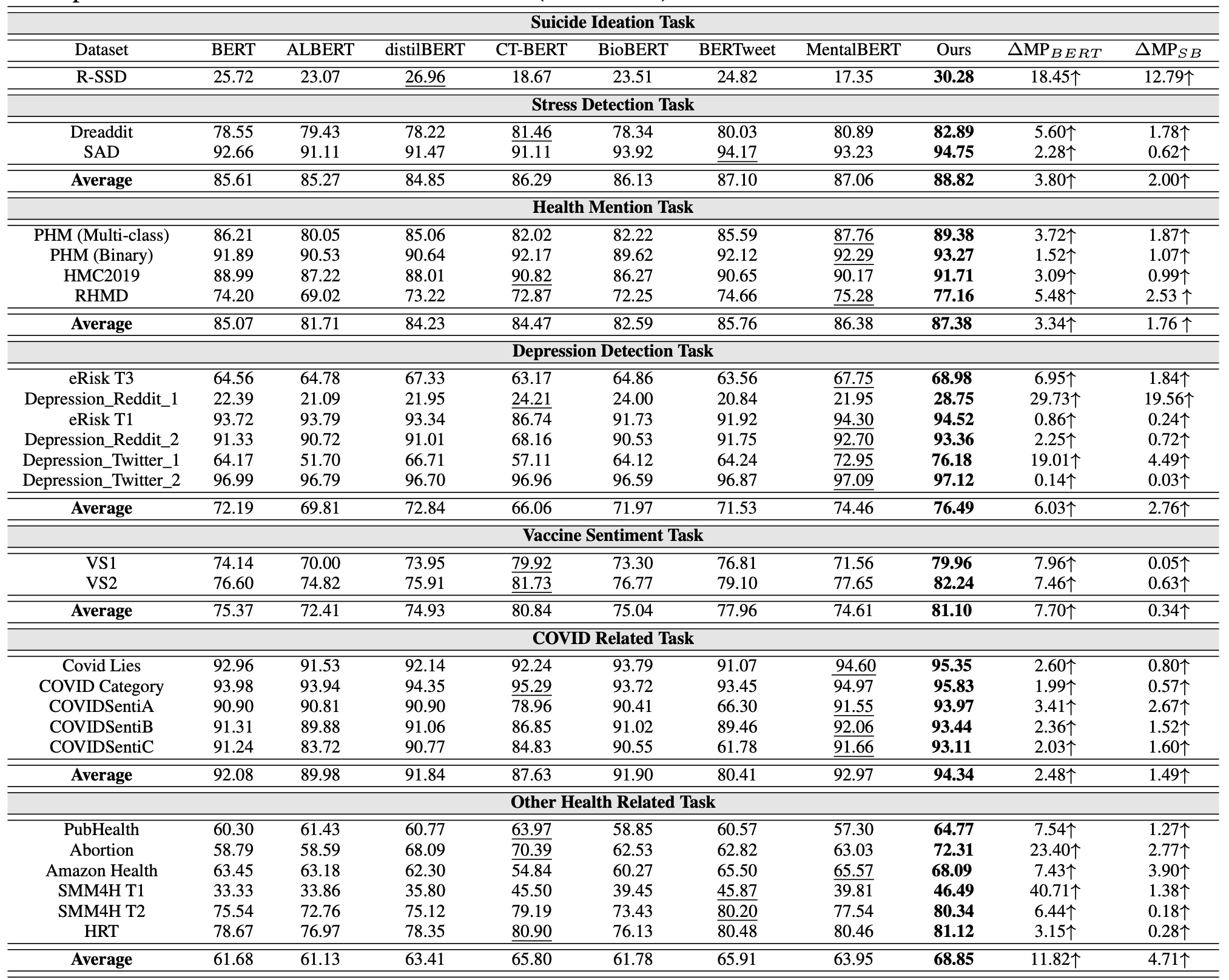
PHS-BERT achieved SOTA f1-scores on the 25 datasets. The second-best results are underlined. ΔMP refers to the marginal increase in performance compared to BERT and the second-best model respectively.